On the Edge

A different kind of edge: Bridal Veil Falls, Yosemite NP. Credit: istockphoto/Charles Wollertz
If you’ve been following the Internet of Things space in the last 2-3 years you have very likely encountered the term edge computing, which now everyone touts as the Next Big Thing. So what’s the hype all about? Unfortunately, there is no generally agreed upon definition of edge computing (yet), so depending on whom you ask (and whatever contraption said person may want to sell to you), you may get slightly different (not to say, contradicting) answers. Some folks here in Europe are apparently working on such a definition (or reference model, or, the Grand Unified Theory of Edge Computing), but nothing except a colorful multi-dimensional layer cake and a press release has come out of it yet.
Where the Action Happens
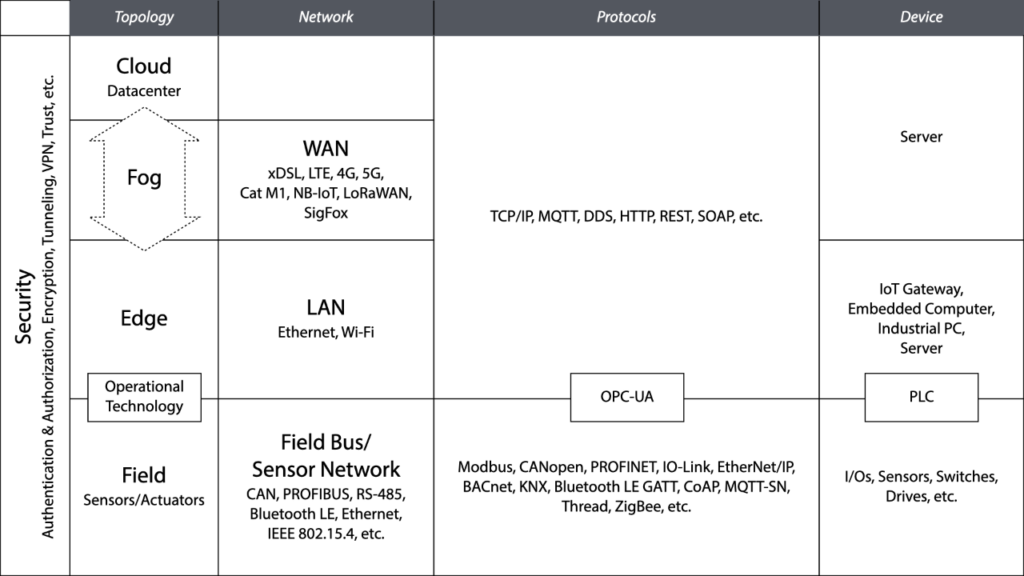
At a very basic level, edge computing means doing interesting stuff with data at or near the place where that data comes from, or where the action happens. This may be a factory floor, or a specific machine on the factory floor, or a car, or even your smart phone. Hopefully that place where interesting stuff with data is happening has some form of internet connectivity (Ethernet, Wi-Fi, LTE/4G/5G), because without internet there’s no edge computing. It just would be plain old, boring, computing, and no one really get’s excited about that anymore. The edge in edge computing refers to the fact that stuff happens at or near the edge of the network, specifically, and practically, a TCP/IP network using internet protocols. The term edge implies that something ends there, in that case it’s the cyberspace. So, literally speaking, if you were to fall over that edge, you would end up in the real, physical world.
Let’s Get Physical
An edge computing system interfaces and interacts with its physical environment (where the interesting data comes from) using sensors and actuators. These can be connected directly to, or integrated into an edge device (think accelerometers and cameras in a smart phone), or via wireless sensor networks, Bluetooth, ZigBee, industrial protocols (Modbus, CAN/CANopen, PROFIBUS, PROFINET), plain old RS-232 and RS-485 serial lines, as well as digital and analog I/Os. In industrial automation, this (sometimes quite rough and dirty) space, often filled with big machinery driven by PLCs and field buses, technology that dates back to the 1970s and 1980s and is referred to as Operational Technology (OT). Edge computing typically happens outside of the cozy, clean, and climate-controlled spaces of data centers.
If you have ever played around with any kind of “IoT starter kit” or “IoT tutorial”, you have probably done something very similar to the following:
- You have connected a sensor (typically, a temperature sensor) to a Raspberry Pi or some other small computer with network connectivity.
- You wrote (or copy-pasted, let’s be honest here) a few lines of code or configuration data to read the current temperature from the sensor and send the value to an IoT cloud service, using a protocol like HTTP or MQTT.
- On the IoT cloud service, you created a dashboard with a graph that showed the temperature data series over the previous 60 minutes or so.
- After a few seconds of initial excitement and then staring at the temperature graph for a few more minutes (and maybe squeezing the temperature sensor in your hands, to see if the damn temperature actually would change), you got bored and moved on to more interesting things, like cooking dinner or walking the dog.
This, quite obviously, is not edge computing. All the “interesting” (if you want to call it that) stuff in the above example happenes in the cloud. Now, the cloud is a wonderful thing, and generally there’s nothing wrong with using its almost unlimited data processing capabilities to do “big data” and “large-scale analytics” and “serverless” and “machine learning”. However, there are scenarios where doing everything in the cloud simply does not work.
High Up in the Clouds
Specifically, in order to do something in the cloud, we first have to move our data there, using the internet. Now, while the internet is pretty reliable and fast nowadays, we all have experienced internet outages of various length and severity, and typically at the most inconvenient moment. We also have experienced that it can take some time for data to be transferred from our local machine to a remote server (and back). This is called latency, and it may range from a few milliseconds to many seconds, depending on different factors, which we often cannot control. So, the cloud is not suitable for anything that’s critical or has “real-time” or “low latency” in its requirements, or where the amount of data to process is just too huge to send over the internet. I certainly would not want my home automation system to be cloud based. Imagine sending the information that you’ve just pressed the light switch to be sent to the cloud, then some logic happening there, then the command to switch on certain lamps coming back. Now imagine what all can go wrong in between. And things have gone wrong, as cloud infrastructure is not immune to failure. Call me old-fashioned, but I still prefer real electrical connections between my light switches and my lamps.
And Back Down on Earth
At the same time, the computing power we have available even in smaller devices (like your smart phone) still increases every year significantly. So let’s make good use of this computing power, and let’s avoid sending huge volume of data across the internet if we don’t need to (think privacy, and also, a significant number of people are not too keen on sending sensitive data from their shop floors across the open internet to an unidentified data center on the other side of the planet).
Now, we already should have a rough idea of what edge computing is. Let’s dig a bit deeper. To be considered an edge computing system, a computer system must possess the following properties:
- The system must perform some non-trivial data processing. This includes, but is not limited to filtering data, aggregating and fusing data from different sensors and other sources, caching or buffering data, basic analysis of data, executing (smaller) machine learning models (neural networks), visualizing data (dashboards), or some form of control logic.
- The system must be programmable, with the capability to change or update the software any time. This can range from a simple rule engine, to a scripting language, to running Docker containers. In some cases, even running a subset of an entire cloud software stack is supported (e.g., AWS Wavelength, although this requires an entire “edge datacenter”, which is a datacenter directly connected to a 5G network for minimal latency, and, honestly, stretches the term “edge” quite a bit). If the device requires a lengthy “firmware update” to change what it does, it’s not edge computing. Instead, edge computing embraces modern DevOps practices, as well as software architecture based on microservices and nanoservices.
- The system must have interfaces to sensors and actuators, or other systems in the local network, in order to acquire sensor (and other interesting) data, or to control physical processes through actuators.
- The system must be capable of interfacing with cloud or on-premises services, typically using protocols like HTTP, MQTT or sometimes AMQP. This includes IoT cloud services that store and further analyze data forwarded by edge systems, and also cloud services for managing a large number of edge computing systems (device management). An important part of this is secure remote access to the edge device, which macchina.io Remote Manager provides.
- The system must be connected to the internet, or at least to a local TCP/IP network, otherwise there’s no “edge”.
With regards to size, an edge computing system can range from a (relatively) constrained device like a Raspberry Pi up to a server rack or even a small mini datacenter in a shipping container, or even the above mentioned datacenter directly connected to a 5G network. Although the latter, at least for me, is not really edge computing any more. There’s the related term “fog computing”, where fog means the entire space between the edge and the cloud, which more accurately would describe such a data center.
Given the different possible sizes of edge computing systems, there are a number of different software frameworks and software platforms that help with the realization of edge computing systems. On the lower-level side (Raspberry Pi, IoT gateways, Industrial PCs) are frameworks with an embedded systems heritage, like our own macchina.io EDGE, which focus on low resource use and efficiency, or Eclipse Kura, if Java is more your cup of tea. These typically run on ARM Cortex A or Intel Atom-based devices with 64 MB to 1 GB of RAM. There are plenty of such devices out there, especially where unit cost of the device matters. An example are connected cars (which pretty much covers every new car sold nowadays), which have so-called telematics control units or smart antennas, an application where macchina.io EDGE is already deployed in millions of devices.
Then there are frameworks like EdgeX, which target devices like larger industry PCs or servers with at least 1-2 GB of RAM. These frameworks typically try to adapt technology that comes from cloud and datacenters to work on edge systems. On a similar level are many platforms that help in various ways with getting Docker containers to run on edge computing systems (e.g., Balena, netFIELD, AWS Greengrass, Azure Edge, ioFog, KubeEdge). And finally there are platforms that target edge data centers, and which provide many of the same capabilities known from the big cloud platforms (AWS Wavelength).
Keeping it Secure
With everything that includes computers and networks, security is where the party is over and everyone wakes up the next day with a headache. This is especially true for the edge, as it sits between the cloud, where we generally have managed the security thing quite decently over the last couple of years, and embedded devices and operational technology, where, well, it’s been an entire different, sad, and depressing story.
Security has many aspects that have to be considered in an edge computing system. The most basic thing is encryption of data whenever it’s sent over the network. This is usually handled by adding a TLS layer below the HTTP and MQTT protocols and no one gets excited about that anymore, as it’s generally a solved issue. Except that we still keep using old protocol versions with known security issues, etc.
We may also want to encrypt the data we store on edge devices, or “data at rest” as it’s called. For that we need to securely manage encryption keys on edge devices, with comes with problems (and hardware solutions in the form of Trusted Platform Modules) of its own.
Then there’s authentication (identifying who is accessing a system) and authorization (determining and restricting what an authenticated account is allowed to do), which we have also solved countless time over the past decades, yet too many times still don’t get right. Authentication and authorization is not just restricted to user accounts, but also to devices. So if a device sends data into your cloud service, you want to be sure that the device really is the device it’s pretending to be. The generally accepted way to handle this is to use X509 certificates. Which, again, require private keys that we need to securely distribute to, and manage on edge devices.
Yet another issue trust, and one aspect of that is that edge devices only run code they are really supposed to run. This is solved by cryptographically signing all software packages (including firmware) that are installed and executed on the device, and then checking the cryptographic signatures before loading and executing any code. Again, not exactly rocket science, but it needs to be done, and done correctly.
And one final aspect is that of securely accessing edge devices. Edge devices are typically located in private networks and are not directly reachable from the internet, which is a very good thing from a security perspective. Nevertheless, it may necessary to be able to access edge devices from outside of their networks. This can be handled via port forwarding (not recommended, unless you want your device to show up in Shodan searches), VPNs (which come with their own issues), or via a solution like macchina.io Remote Manager, which manages secure tunnel connections to edge devices, which can, after proper authentication and authorization, be used to access these edge devices via protocols like HTTP (i.e., for accessing the edge device’s web user interface), SSH (for low-level trouble-shooting of Linux-based edge devices) and other TCP-based protocols.
How to Get Started
Hopefully this blog post gave you a good idea of what the current edge computing hype is all about. In up-coming follow-up posts I will show how to build an edge computing application around macchina.io EDGE and macchina.io Remote Manager, by integrating it with other open source technologies like Docker, Portainer and InfluxDB. Stay tuned!